Glossar
Anwendungsfall
Batchjob
Change Request
DAU
Day
by Day Management
Dreischicht-Architektur
EVA
Function Point Analyse
Gap Analysis
Komplexitätstheorie
Lernprozess
Murphys Gesetz und der
Murphyfaktor
Paretoregel
Refactoring
Screenshot
Story Board
Test
UML - unified modelling language
Falls Sie einen Begriff vermissen oder
nicht verstehen, dann schreiben Sie mich bitte an (Kontakt)!
Anwendungsfall
Der Anwendungsfall (use case) beschreibt einen konkreten Ablauf im
Sinne des EVA-Prinzips, wobei neben Eingabe,
Verarbeitung und Ausgabe noch Akteure (also Personen und Systeme, die
bestimmte Arbeitsschritte vollziehen) und Randbedingungen beschrieben
werden. Anwendungsfälle werden im Rahmen der UML
(unified modelling language) benutzt und stellen eine strukturierte
Darstellungsform dar.
Anwendungsfälle werden normalerweise aus Anwendungsszenarien
hergeleitet. Ein Anwendungsszenario ist ein konkretes Beispiel, der
Anwendungsfall verallgemeinert die Beispiele und bildet viele
ähnliche Beispiele innerhalb eines Regelwerks ab.
Ein Anwendungsfall ist sehr klar definiert und gegen andere
Anwendungsfälle abgegrenzt, sodass für jeden Anwendungsfall
ebenso klare Testfälle definiert werden können.
Der Begriff Anwendungsfall wird innerhalb der IT etwas schwammig
benutzt. So kann ein einzelner abgeschlossener Benutzerdialog als ein
einziger
Anwendungsfall betrachtet werden, oder aber er kann ein ganzes
Teilsystem
umfassen. [Fowler2] S. 42
spricht
z.B. von ca. einem Dutzend Basis-Anwendungsfällen in einem
Projekt,
das zehn Personenjahre umfasst, verweist jedoch auf andere Projekte
derselben
Größenordnung mit über hundert Anwendungsfällen.
Bricht man die Beschreibung einer Anwendung bis auf Bildschirmebene
herunter
(und dies muss man, wenn ein Anwendungsverhalten vollständig
beschrieben
sein soll) und beschreibt jeden dieser Vorgänge als
Anwendungsfall,
so kann man bereits bei Anwendungen in der Größenordnung
einiger
Personenmonate auf mehrere Dutzend Anwendungsfälle kommen.
Im Kapitel Inhalt eines Anforderungsdokuments
wird der Anwendungsfall im Detail erklärt.
Batchjob
Ein Batchjob ist ein Prozess, der unabhängig vom Anwender
irgendwann läuft, meist nachts in einer betriebsarmen Zeit. Ein
Dialog mit dem Anwender, d.h. Bildschirmeingaben, finden nicht statt.
Der
Name stammt noch aus dem Lochkarten-Zeitalter. Ein batch war ein Stapel
von Lochkarten. Heutzutage hört man nur noch selten den Begriff
Stapeljob, allerdings hat sich auch der Begriff offline-Verarbeitung
noch
nicht komplett durchgesetzt.
Solche Prozesse werden z.B. für zeitintensive Abrechnungsprozesse
von
Massendaten oder administrative Aufgaben wie Datensicherungen benutzt.
Change Request
Ein Change Request ist ein Änderungsantrag. Dabei wird gefordert,
dass ein vorhandenes Feature einer Anwendung geändert oder ein
neues Feature hinzu
gefügt wird.
Ein Change Request durchläuft den vollständigen
Software-Entwicklungs-Prozess. Zunächst wird also auch zum
Change Request eine Analyse geschrieben. Es ist nichts
ungewöhnliches, dass sich dabei heraus stellt, dass es eine Reihe
anderer Wege mit oder um das vorhandene IT-System herum gibt, um das
gewünschte
Ergebnis zu erzielen. Anschließend werden die notwendigen
Modifikationen
im Software-Design erarbeitet, schließlich wird das Feature
implementiert und am Ende auch getestet. Der Testaufwand selbst
für kleine
Feature-Änderungen kann sehr groß werden, da meist ein
komplettes
Nachfahren aller Tests des betroffenen Prozesses (Regressionstest)
notwendig ist, um alle Nebenwirkungen der Änderung zu erfassen.
Über die Annahme und Priorisierung oder Ablehnung eines Change
Requests entscheidet das Change Board, ein Gremium, in dem sowohl
Mitarbeiter der Fachabteilung als auch der IT-Abteilung sitzen.
Betrachtet man ein ganzes Unternehmen als ein einziges großes
Projekt so kann der Lenkungsausschuss als Change Board verstanden
werden. In Einzelfällen kann auch ein Projektleiter alleine einen
Change Request ablehnen, nicht jedoch alleine annehmen.
DAU
Dümmster anzunehmender User.
Die im IT-Support und der Software-Entwicklung gängige
Abkürzung DAU lehnt sich an GAU (größter anzunehmender
Unfall) an. Gemeint damit sind Anwender, die sehr häufig den
Support kontaktieren und i.d.R. auf nicht sehr höfliche Art und
Weise ihren Unmut über das nicht-Funktionieren eines IT-Produkts
kundtun, wobei sich schließlich regelmäßig heraus
stellt, dass der fragliche Anwender selbst die Funktionsstörung
verursacht hat, oder dass die Behebung der vermeintlichen Störung
in seinen Arbeitsbereich fällt.
Typische Beispiele sind Drucker, die auf offline gestellt wurden oder
denen das Papier ausgegangen ist (Fehlermeldung: "Mein Drucker druckt
nicht!"); Leute, die Monitore ausgeschaltet oder bei der
Helligkeitseinstellung auf vollkommen dunkel gestellt haben ("Rechner
geht nicht."); Anwender, die bestimmte Produktfeatures nicht
korrekt nutzen ("Kann Datensatz X nicht löschen." - "Kein Wunder,
den haben Sie gestern schon gelöscht.") ; oder Anwender, die die
Gebrauchsanleitung nicht gelesen haben ("X geht nicht." - "Kein Wunder,
Funktionaliät X ist auch nicht implementiert, das machen Sie seit
jeher manuell.")
Ebenso fallen in dieses Ressort die aus dem echten Leben stammenden
typischen IT-Witze (Support: "Was steht denn auf dem Monitor?" - DAU:
"Eine Blumenvase.") oder Geschichten, die das Leben schreibt (z.B.
nicht mehr lesbare Disketten, da sie mit einem Magneten an einen
Stahlschrank geheftet wurden, CDs, die gelocht und in einen Leizordner
einsortiert werden).
In der Business Analysis werden damit Fachanwender bezeichnet, die sich
widersprechende Forderungen stellen, keine konkreten Auskünfte und
Details zu ihren Forderungen nennen oder die ihre Meinung
regelmäßig ändern, u.U. hin und her.
Day by Day Management
Normalerweise wird geplant, aber ebenso normal ist es, dass Planungen
nicht eingehalten werden. In diesem Fall werden die Planungen dynamisch
an die Wirklichkeit angepasst. Managementaufgabe ist es dabei,
zumindest den Zeit- und Kostenplan einzuhalten.
Gerät ein Projekt jedoch vollkommen aus dem Ruder, so ist jede
weitere Planung sinnlos. Solche Projekte sind mit einem Flugzeugabsturz
zu vergleichen. Dabei geht es nur noch ums nackte Überleben.
Für ein Projekt bedeutet dies, dass es zunächst wieder in
einen kontrollierbaren und somit planbaren Zustand überführt
werden muss. Die dazu geeignete Technik ist das Day by Day Management.
Ein Arbeitstag sieht
dabei etwa wie folgt aus:
- Erste Tagesaktivität ist die Feststellung der aktuellen
Probleme. Die Probleme werden nach Wichtigkeit sortiert.
- Die so sortierte Problemliste wird am laufenden Tag soweit wie
möglich abgearbeitet. Stellen sich unüberwindbare Hindernisse
heraus, so wird das Problem nicht weiter verfolgt, sofern dies
möglich ist. Statt dessen wird ein work-around definiert und
implementiert.
- Zwischendurch wird auch tagsüber die Problemliste
aktualisiert.
- Abends wird Bilanz gezogen und dokumentiert, was als
nächstes zu tun ist. Soweit möglich werden noch Ressourcen
angefordert, die in den nächsten Tagen benötigt werden.
- Der aktuelle Stand der Dinge wird berichtet, sodass das
vorgesetzte Management am Morgen des nächsten Tages helfend
eingreifen
kann.
Betreibt ein Projektmanager Day by Day Management, so sollte er sich
mit Terminzusagen oder Versprechungen zurück halten. Das
Berichtswesen beschränkt sich lediglich auf den aktuellen Status
und die wesentlichen Probleme und die zugehörigen
Lösungsvorschläge. Neue Anforderungen werden keinesfalls
aufgenommen.
Man sollte sich von dem Begriff Day by Day Management nicht
beeindrucken lassen. Er wird gerne von Leuten benutzt, die keine all zu
großen organisatorischen Fähigkeiten haben und schlichtweg
nicht in der Lage sind, vernünftige Planungen aufzustellen. Ein
sicheres Zeichen dafür, dass man es mit dem Gegenteil eines
Organisationstalents zu tun hat, liegt in der Aussage, dass Day by Day
Managenement betrieben wird, obwohl gar keine Krise vorliegt.
Dreischicht-Architektur
Von einer Dreischicht-Architektur spricht man bei IT-Systemen, wenn
physikalische Datenhaltung, Geschäftslogik und
Benutzeroberfläche strikt getrennt sind.
Dieser Ansatz ist state of the art. Zwischen den drei Schichten
bestehen klar definierte Schnittstellen. U.U. gibt es noch mehr
Schichten, die sich dann allerdings eher mit der Übersetzung von
Informationen beschäftigen. So kann z.B. eine physikalische
Datenzugriffsschicht und eine logische Datenzugriffsschicht kombiniert
werden, um den Austausch der von der physikalischen Zugriffsschicht
bedienten Datenbank zu erleichtern. Zwischen Benutzeroberfläche
und Geschäftslogik kann eine weitere Übersetzungsschicht
eingezogen werden, damit ggf. die Ablösung einer
entwicklungsumgebungsspezifischen Oberfläche erleichtert wird. Bei
der Benutzeroberfläche spricht man bei dieser Architektur
übrigens von einem thin client. Dieser Ansatz ist sehr
wartungs- und änderungsfreundlich, die Wiederverwendbarkeit
einzelner Komponenten ist relativ leicht zu erreichen.
Diesem Ansatz stehen die Philosophie des fat client und der
Ansatz, dass die Geschäftslogik in die Datenbank gehört,
gegenüber.
Beim fat client werden Geschäftslogik und Benutzeroberfläche
zusammen gefasst, und die Zugriffe auf das Datenhaltungssystem sind
ebenfalls fest einkodiert. Solche Ansätze werden von unerfahrenen
Entwicklern bevorzugt, oder um (zu Lasten von Wartbarkeit und
Wiederverwendbarkeit des Systems) Zeit zu sparen. Der quick hack ist
fast immer ein fat client.
Wird die Geschäftslogik in die Datenbank gelegt, so entstehen
starke Abhängigkeiten vom benutzen Datenbanksystem. Da
Dialogfunktionen immer wieder auch geschäftslogische Operationen
erfordern, ist es in den seltensten Fällen möglich und
sinnvoll, die gesamte Geschäftslogik in die Datenbank zu legen. Da
jedoch kein System schneller auf die Daten zugreifen kann als die
Datenbank selbst, werden Massenverarbeitungen,
z.B. Abrechnungsprozesse, fast immer in der Datenbank angesiedelt.
EVA
EVA steht für Eingabe - Verarbeitung - Ausgabe. Es handelt sich
hier um eine Black Box - Betrachtung eines IT-Systems oder eines
beliebigen Prozesses.
Die Eingabe umfasst alle in das System eingehenden Daten. Historisch
gesehen war dies ein Stapel Lochkarten, der gelesen wurde. Gemeint
damit sind jedoch alle Daten von der Bildschirmeingabe über aus
Dateien oder Datenbanken gelesene Daten bis hin zu abgreifbaren
Systemzuständen (z.B. Datum und Uhrzeit,freier Hauptspeicher),
Signalen von Messgeräten o.ä.
Die Verarbeitung umfaßt im IT-Modell Hard- und Software. Der
Computer macht die Arbeit, ohne dass der Anwender weiß, wie das
passiert. Solch eine Betrachtungsweise ist nichts ungewöhnliches:
Wer weiss schon im Detail,
wie ein Motor funktioniert und trotzdem setzt sich jeder in Fahrzeuge.
Die Verarbeitung fasst alle notwendigen Arbeitsschritte in Form eines
Regelwerks und ggf. in Form von Werkzeugen im weiteren Sinne zusammen,
die auf die eingegebenen Daten angewendet werden und zur Ausgabe
führen.
Die Ausgabe sind die Ergebnisse aus den verarbeiteten Eingaben, also
z.B. Bildschirmausgaben, Dateien, in Datenbanken archivierte Daten oder
Druckausgaben. Historisch gesehen kam am Ende des
Datenverarbeitungs-Prozesses eine Druckliste aus einem Drucker.
Das Prinzip läßt sich u.a. auf jede Art von
Geschäftsprozess, Verwaltungsarbeit oder industriellen
Fertigungsprozess übertragen. Auto fahren mag als Beispiel
hilfreich sein: Eingaben sind etwas reduziert betrachtet das Drehen am
Lenkrad, die Betätigung von Kupplung und Bremse. Die Verarbeitung
sorgt dafür, dass das Fahrzeug sich von der Stelle bewegt. Als
Ausgabe sieht man die Tachonadel oder die Tankanzeige. Als Ergebnis
(also auch eine Form der
Ausgabe) kann auch die Ankunft am Zielort betrachtet werden. Es
gibt unendlich viele Zielorte, die alle durch dieselben
Verarbeitungsmechanismen erreicht werden können, und die
abhängig von den
Eingaben sind. Bei einer vollständigen Betrachtung des
Gesamtsystems Auto fahren müßten noch eine Vielzahl von
Parametern betrachtet werden, z.B. das Betanken des Fahrzeugs oder die
Sehfähigkeit des Fahrers oder auch die
Geleändegängigkeit des Fahrzeugs (Systembeschränkungen).
Man sieht hier schon die Tücken eines IT-Systems: Zwar muss der
Motor zuerst angelassen werden, aber
mit dem Fahrvorgang selbst hat das nichts zu tun. Zwar darf nur ein
Führerscheininhaber legal Auto fahren, aber dennoch werden viele
Leute beim Schwarzfahren erwischt. Zwar muss Benzin im Tank
sein, aber immer wieder bleibt ein Auto deshalb liegen. Zwar sollte
man nachts das Licht anmachen, aber zwingende Bedingung dafür,
dass das Auto rollt, ist das nicht. Zwar ist der Gipfel des Matterhorns
ein für Menschen erreichbarer Ort, aber mit einem Reisebus kommt
man
nicht bis ganz hinauf. Sind dies nun zu berücksichtigende
Parameter im Rahmen der Eingabe oder Verarbeitung oder nicht?
Wesentlich ist: Es gibt keine verborgenen Konstanten oder Variablen.
Das Prinzip führt zu einem wesentlichen Paradigma der Informatik: Jeder
Zustand eines IT-Systems hat abhängig von den zugeführten
Eingabedaten einen genau definierten Folgezustand. Somit
läßt sich eine gewöhnliche Anwendung durch eine
Typ-3-Grammatik im Sinne von Chomsky bzw. durch einen finiten Automaten
abbilden. Das Ergebnis einer solchen vollständigen Beschreibung
ist ein Story Board.
Function Point Analyse
Function Points werden benutzt, um Aufwände für
Software-Projekte zu ermitteln. Dabei handelt es sich um einen
ursprünglich von IBM entwickelten Ansatz, der von
der IFPUG (International Function Point Users Group) aufgenommen und
weiter entwickelt wurde. Das Prinzip ist sprachen- und
plattformunabhängig, die Abschätzung wird also lediglich auf
Grund der Anforderungsanalyse vorgenommen, also aus funktionaler bzw.
aus Benutzersicht.
Bei dieser Analysemethode wird jede einzelne
spezifizierte Funktionalität bewertet, wobei eine bestimmte
Vergabemethode für Punkte angewendet wird, die von der IFPUG
definiert wurde. Die Anzahl der Datenquellen ist eines dieser
Bewertungskriterien, ein anderes die Verknüpfung von Daten
innerhalb einer Funktion. Gemeint damit ist, dass z.B. das reine Lesen
und Anzeigen von Daten aus einer Datenbank einfacher und schneller zu
implementieren ist,
als das Lesen von Daten von einem Bildschirmformular, dessen
Prüfung, die Ausgabe von ggf. notwendigen Fehlermeldung, die
Berechnungen,
die mit diesen Daten anzustellen sind, und schließlich das
Abspeichern.
Die Function Point Analyse gibt lediglich die Komplexität und
daraus herleitbaren Aufwände wieder. Um zum tatsächlichen
Aufwand zu kommen, müssen noch Randbedingungen über das
Produkt, die Qualifikation des Personals, die ausgewählte
Entwicklungsplattform und das Projekt selbst berücksichtigt werden.
google über die Function Point Analyse
Gap Analysis
Bei der Gap Analysis wird die zu überbrückende
Lücke zwischen einem vorhandenen System und einem
Geschäftsprozess, der mit diesem System abgewickelt werden soll,
analysiert. Will man das vorhandene System benutzen, dann wird das
Anforderungsdokument als Basis für die notwendigen
Anpassungsarbeiten benutzt.
Komplexitätstheorie
In der Komplexitätstheorie wird eine Klassifizierung von
algorithmischen Problemen vorgenommen. Grob gesprochen wird dabei
unterteilt, wie stark die Rechenzeit bei linear steigender Datenmenge
zunimmt. Das Spektrum reicht von linearer Zunahme (z.B. die Addition
von
Zahlen), über polynomiell (z.B. Sortierung von Zahlenreihen, sog.
p-Probleme), weiter über exponentiell (np-Probleme) bis hin zur
"überexponentiell" (np-vollständig). - Die Mathematiker unter
Ihnen mögen mir diese lockere Unterteilung bitte verzeihen.
Für Business Analysten sind derartige Betrachtungen nur selten
relevant, sie helfen aber, vollkommen unhaltbare Anforderungen zu
erkennen.
google über Komplexitätstheorie
wikipedia zur np-Vollständigkeit
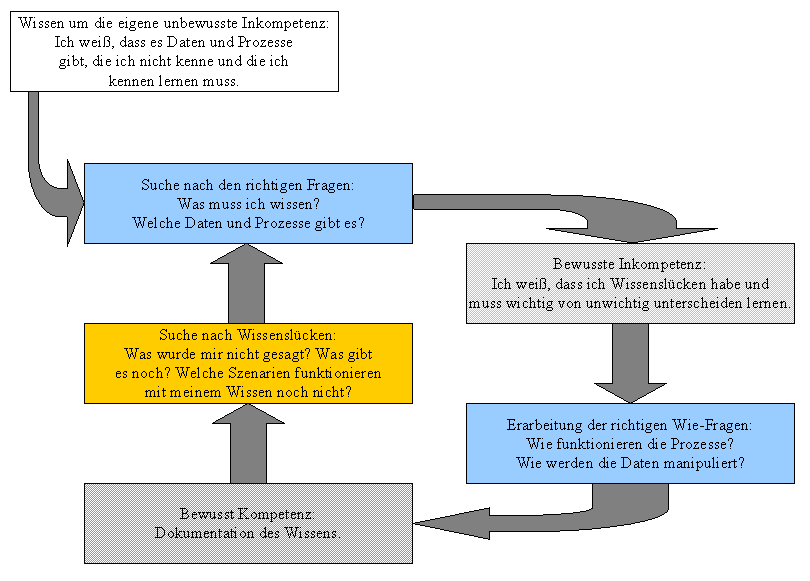
Lernprozess
Lernen bedeutet, dass man sich eine Fertigkeit aneignet. Das reine
Wissen ist graue Theorie und ohne die Fertigkeit, dieses Wissen in
irgendeiner Form auch anzuwenden, ist das Wissen nur als
Gedächtnisleistung bemerkenswert. Ein Bild für das
Verständnis des Lernprozesses kann der stufenweise Fortschritt von
der unbewussten Inkompetenz zur unbewussten Kompetenz sein:.

- Befindet sich ein Mensch im Zustand der unbewussten
Inkompetenz, so weiß er
nicht, dass er etwas nicht weiß bzw. nicht kann. Jemand, der noch
nie ein Auto gesehen hat und noch nie davon gehört hat, kann nicht
Auto fahren und weiß auch nichts vom Auto fahren. - Er weiß
nicht, welche Fragen er stellen muss.
- Durch irgendein meist zufälliges Ereignis oder einen
Einfluss von außen erreicht ein Mensch den Zustand bewusster
Inkompetenz. Dabei weiß
er, dass es etwas gibt, das er nicht kann bzw. nicht vollständig
kennt, und bei dem jede Kenntnis nur theoretisch ist. Wissen ohne
Fähigkeit, dieses Wissen anzuwenden. Die Vorstellung ist vage,
aber immerhin weiß er jetzt, wo er suchen muss. Ein Mensch in
diesem Zustand kann sich nach freiem Willen entscheiden, ob
er die fragliche Fertigkeit lernen will, oder nicht. Beim Bild des
Auto fahrens kann man sich jemanden ohne Führerschein vorstellen.
- Im Zustand bewusster Kompetenz kann ein Mensch eine
Fertigkeit ausüben bzw. sein theoretisches Wissen anwenden. Aber
die Anwendung ist mühsam, jeder
Schritt muss sorgsam geplant und überlegt werden. Dieser
Zustand ist vergleichbar mit den ersten Fahrstunden.
- Irgendwann kommt die Routine, das Nachdenken hört auf, und
die Fertigkeit wird von alleine eingesetzt. Von der bewussten
Kompetenz wurde in die unbewusste Kompetenz gewechselt. Beim
Auto fahren kann man hier die bestandene Führerscheinprüfung
sehen, aber vom Führerschein-Neuling bis zum Formel-I-Weltmeister
ist noch immer ein weiter Weg.
Für normale Menschen reicht dieses Bild. Für einen Business
Analysten ist das aber nur die halbe Wahrheit. Er lernt nicht, er nutzt
den Lernprozess bewusst. Auch lernen will gelernt sein. Wenn man den
Lernprozess auf sich selbst anwendet und sich somit auf eine Ebene des
Metalernens begibt, kann eine
effektive Methode entwickelt werden,
wichtige von unwichtigen Informationen zu unterscheiden.
Zu wissen, dass man nichts weiß,
hilft nicht weiter. Wenn man nicht weiß, welche Fragen
man stellen muss, bewegt man sich in einer Grauzone zwischen
unbewusster Inkompetenz und bewusster Inkompetenz. Ein Analytiker ist
sich darüber immer im
Klaren. Deshalb sucht er zuerst nach den
richtigen Fragen, und dabei helfen ihm seine Fachanwender. Das, was der
Business Analyst sieht, versteht er zunächst nicht, aber der
Prozess des Begreifens des Gesehenen führt
zu den richtigen Fragen die klar werden lassen, welche Prozesse und
Daten es gibt. Eine Unterscheidung zwischen relevanten und irrelevanten
Informationen bzw. eine Priorisierung derselben ist noch nicht wirklich
möglich.
Anschließend müssen die Daten
und Prozesse und deren Auswirkungen auf das Geschäft verstanden
werden, und erst hier kann eine Unterscheidung in wichtig und
unwichtig stattfinden. Zwar befindet man sich dann in einem Zustand
bewusster Kompetenz, der für eine Spezifikation auch vollkommen
ausreicht, aber der Analytiker kann nicht davon ausgehen, dass ihm
der Fachanwender "freiwillig" alle
relevanten Informationen gegeben
hat. - Etwa hier steigt ein Analytiker ein, der bereits sehr solides
Know How über das zu untersuchende Fach hat. D.h. dass er auf
Grund seiner potentiellen Betriebsblindheit oder seiner Vorurteile
bereits
Prozesse und Daten und deren Auswirkungen auf das Geschäft
übersehen
haben kann und auch nicht den nächsten wichtigen Schritt hin zu
einem
nicht nur vollständigen und korrekten, sondern auch die Arbeit
erleichternden, hilfreichen und komfortablen System vollzieht: Die
Suche
nach Lücken in den Abläufen.
google zu ein paar Schlagwörtern des
Lernprozesses
Murphys Gesetz und der Murphyfaktor
Ein gewisser Ed Murphy, Ingenieur, schrieb einmal Geschichte. Genau
genommen schrieb nicht er selbst Geschichte, sondern ein besonders
begabter Techniker in seinem Team. Dieser Techniker hatte wieder einmal
etwas verkehrt herum angelötet, worauf es Murphy entfuhr: "Wenn er
etwas verkehrt machen kann, dann macht er es verkehrt." Damit war
Murphys Gesetzt (Murphys Law) geboren: Wenn
etwas schief gehen kann, dann geht es auch schief. (If anything can
go wrong it will!) Inzwischen gibt es hunderte Ableitungen oder
Abwandlungen, die von Murphys Gesetz für Behörden (Wenn etwas
schief gehen kann, dann in mindestens vierfacher Ausfertigung) bis
zum Gesetz der selektiven Schwerkraft (Die Wahrscheinlichkeit, dass ein
Butterbrot mit der mit Butter beschmierten Seite nach unten auf
den Teppich fällt, steigt, je höher die Reinigungskosten
des Teppichs sind) reichen. - Das alles klingt zwar lustig, ist aber
bitterer Ernst. Ich hatte im Studium einen Professor, der
hartnäckig darauf beharrte, dass Murphy ein unverbesserlicher
Optimist sei.
In der IT hat man sich mit dieser Gesetzmäßigkeit bereits
frühzeitig auseinander gesetzt und einen Unsicherheitsfaktor
eingeführt, den ich den Murphyfaktor
nenne. Dieser Murphyfaktor ist ein Maß für nicht erkannte
und versteckte Fehler, Tücken, Kosten und Aufwände. Mit
diesem empirisch
ermittelten Faktor werden Schätzungen multipliziert, z.B. für
die Entwicklungsdauer eines Projekts oder die Datenmenge, die zur
Verarbeitung anfallen wird. Genaue Methoden, den Murphyfaktor zu
ermitteln, gibt es m.W. nicht. Er wird fallabhängig und
abhängig von den bisherigen Erfahrungen des Schätzers oder
durch Konsensfindung im Team gewählt. Besondere
Abhängigkeiten für den Business Analysten finden sich in der
Komplexität der Materie, in der Sachkenntnis des Analytikers im zu
analysierenden Fach, der Menge der Interfaces zu anderen Systemen, der
Menge der Datenquellen aus anderen Systemen, in der
Kommunikationsfähigkeit und den sozialen Kompetenzen seiner
Ansprechpartner, in der Größe des Kreises der Entscheider,
die über die Richtigkeit
und Notwendigkeit einer Anforderung befinden, sowie in der Menge der
von
den Entscheidern konsultierten Spezialisten. Für Zeiten und
Aufwände
sind kunden- und komplexitätsabhängig nach meinen Erfahrungen
Faktoren zwischen 1,3 und 2,8 anzusetzen.
Schon Tom DeMarco hat in seinem beachtenswerten
Buch "Wien wartet auf Dich" (Peopleware) den Faktor Mensch in
IT-Projekten untersucht [DeMarco1].
Seine Ergebnisse lassen den Schluss zu, dass die Effizienz einer
Organisation relativ stabil ist, und die Effizienz verschiedener
Organisationen beim gleichen gestellten Problem etwa um den Faktor
10 (das ist kein Tippfehler!) voneinander abweichen kann. Besonders
beachtenswert sind dabei die Arbeitsbedingungen der Mitarbeiter,
insbesondere, wie sehr sie gestört werden können.
Großraumbüros, Lärm, nicht abzuschaltende Telefone,
Projektleiter, die unangemeldet bei Entwicklern vorbei schauen und auf
die Schnelle deren Denkarbeit
unterbrechen o.ä. können als Indizien für eine weniger
effiziente Organisation angesehen werden. Der Murphyfaktor sollte
in diesem Fall hoch angesetzt werden.
google zu Murphys Gesetz (führt eher zu
spassigen Seiten)
Paretoregel
Die Paretoregel wird im Rahmen des Zeitmanagements
regelmäßig zitiert. Sie besagt, dass 80% der Arbeit
in 20% der Zeit erledigt werden kann. Sie ist auch unter den Begriffen
Paretoprinzip oder pareto law bekannt.
Diese Sichtweise ist m.M. nur aus einem strategischen Blickwinkel
korrekt und kann sehr leicht im Rahmen eines IT-Projekts bzw. bei einer
Analyse zum Selbstbetrug führen. In 20% der Zeit erarbeitet man im
Rahmen einer Analyse bestenfalls eine "high level - Sicht" auf die zu
untersuchenden Abläufe, die zwar als Entscheidungsgrundlage
für die Gestaltung von Prozessabläufen hilfreich sein
mag und evtl. schon für einen ersten Wegwerf-Prototypen ausreicht,
aber die für ein IT-Projekt notwendige Details noch nicht einmal
berührt hat. Gar nicht anwendbar ist die Paretoregel bei den
Leuten, die die echte Arbeit machen, die also nichts weiter delegieren
können oder als Spezialisten die einzigen Leute im Unternehmen
sind, die eine konkrete Aufgabe lösen können.
google zur Paretoregel bzw. zum Paretoprinzip
Refactoring
Bei iterativen Prozess-Modellen ist es notwenig, das Software-Design
den Anforderungen der neuen Produktversion anzupassen. D.h. auch, dass
Teile des Progammcodes bei der Weiterentwicklung von Produktversionen
umgeschrieben werden müssen, nur um ihn dem neuen Design
anzupassen und ohne dass dadurch neue (für den Anwender sichtbare)
Funktionalitäten implementiert werden. Bei diesem Prozess spricht
man vom Refactoring des Codes. Man kann davon ausgehen, dass mindestens
10% des vorhandenen Codes von Version zu Version umgeschrieben werden
muss. Falls es weniger ist, dann ist etwas faul.
Man kann von Nicht-IT-Spezialisten kein Verständnis für
diesen Prozess erwarten, als Nicht-IT-Spezialist sollten Sie Ihren
Leuten einfach nur glauben, dass Refactoring unvermeidbar ist.
Screenshot
Ein Screenshot ist lediglich eine Bildschirmkopie,
die i.d.R. als Graphik nachbearbeitet und in ein Dokument
eingefügt wird. Um unter windows einen Screenshot zu bekommen,
drückt man
auf Druck bzw. bei englischen Tastaturen auf Print.
Eine
Kopie des Bildschirms wird dann als Graphik in den Zwischenspeicher
geschrieben. Diese Kopie kann mit der Einfügefunktion bzw. auch
strg-v z.B. in ein Graphikprogramm oder ein Textverarbeitungsprogramm
eingefügt
werden.
Story Board
Im Rahmen der Entwicklung eines IT-Systems, das Dialoge mit dem
Anwender führt, spricht man bei einem Story Board (vor allem) von
der Beschreibung der Bildschirmformulare des Systems. Zu jedem Formular
wird eindeutig definiert, was passiert, wenn das Formular verlassen und
die Kontrolle vom
System übernommen wird. Bei einer funktionierenden Anwendung
führt jedes Formular zu einem definierten Folgeformular, bis
schließlich ein definierter Endzustand erreicht ist.
Auch Fehlerzustände des Systems können so kontrolliert
werden; so kann z.B. eine falsche Eingabe in einem Editfeld
nach dem Drücken eines speichern-Buttons zu einem anderen Formular
führen, in dem der Fehler dargestellt wird. Alternativ und nicht
unüblich ist, dass das ursprüngliche Formular nochmals neu
geladen wird und die Fehlermeldung wird in diesem Formular
platziert. Zu klären ist hier natürlich, was mit den
eingegebenen Daten passieren soll: sollen sie im durchgeladenen
Formular erhalten
bleiben, oder soll das Formular ganz oder teilweise zurück gesetzt
werden?
Es hat sich noch nicht überall herum gesprochen, dass Story Boards
nichts anderes als
finite Automaten (finite state machines) bzw. Typ-3-Grammatiken im
Sinne von Chomsky sind, die vollständig tabellarisch abgebildet
und nach standardisierbaren Prinzipien analysiert werden
können. Dass dies so ist beruht auf einem Paradigma der
Informatik,
das besagt, dass eine Anwendung abhängig von den gerade
betrachteten
Daten von einem wohl definierten Zustand, in dem sie sich gerade
befindet,
in genau einen ebenso wohl definierten Folgezustand wechselt. Diese
betrachteten Daten sind bei Bildschirmformularen eingetippte bzw.
ausgewählte Daten und gewählte links bzw. gedrückte push
buttons. Das Resultat dieser Unkenntnis und der z.T. haarsträubend
unvollständigen
und unscharfen Darstellungen schon alleine der Abfolge der
Benutzerdialoge
schlägt sich in entnervten Entwicklern nieder, die
schließlich eigene Formulare entwickeln oder vorhandene
modifizieren müssen, oder aber in Anwendungen, die insbesondere
bei Fehleingaben in undefinierte Fehlerzustände geraten und
abstürzen.
Im Kapitel Inhalt eines Anforderungsdokuments
wird das Story Board im Detail erklärt.
Test
Teil der Qualitätssicherung einer Software ist der Test. Dabei
werden Testszenarien erarbeitet, die jede mögliche Konstellation
der Software so gut wie möglich erfassen. Tests finden auf allen
Ebenen der Entwicklung statt, auf unterester Ebene ist dies der unit
test (Modultest), den der
Programmierer für einzelne von ihm implementierte
Funktionalitäten
durchführt, auf obererster Ebene ist es der acceptance test
(Abnahmetest),
bei dem die Software gegen die Spezifikation geprüft wird.
Man unterscheidet in Postiv- und Negativtests. Der Positivtest wird
häufig einfach nur Test genannt, der Negativtest häufig
Provokation.
Beim Positivtest wird das ideale Verhalten der Anwendung bzw. auch des
Anwenders geprüft. Dabei werden ausschließlich richtige
Daten
im geplanten Wertebereich verwendet, Bildschirmformulare werden
prinzipiell
korrekt und vollständig ausgefüllt, Schnittstellen werden
korrekt
beliefert etc. Zweck des Positivtest ist es nachzuweisen, dass die
Anwendung
das tut, was spezifiziert ist.
Beim Negativtest werden andere vorstellbare Situationen und
Katastrophen simuliert. Z.B. werden Bildschirmformulare nicht
vollständig ausgefüllt, falsche oder ungültige Werte
werden eingetragen, Laderoutinen werden mit fehlerhaften, leeren oder
gar keinen Dateien versorgt, die Datenbankverbindung wird unterbrochen,
die Integrität der Datenbank wird verletzt (sofern dies nicht von
der Datenbank selbst verhindert wird) etc. Zweck des Negativtests ist
es, die Sicherheit der Anwendung gegen falsche Bedienung und technische
Störungen zu prüfen.
UML - unified modelling language
UML ist gerade modern und der aktuelle Versuch einen Standard zu
schaffen, um im Rahmen eines einheitlichen Vorgehensmodells eine
Anwendung von der Anforderungsanalyse bis zur Implementierung zu
beschreiben.
Dabei werden im Rahmen der Anforderungsanalyse im Anforderungsdokument
u.a. Anwendungsfälle definiert und
z.T.
auch graphisch dargestellt. Aus den Anwendungsfällen wird auf eine
sehr klar definierte Weise Architektur, Design und Implementierung
entworfen, ehe die Kodierung und der Test folgen. UML ist keine Methode
und auch
kein Prozess, um Anwendungen zu entwickeln, sondern eine Sprache, um
das
Verhalten einer Anwendung zu beschreiben. UML ist ein fester
Bestandteil
des RUP (rational unified process), kann aber in jedem anderen
Prozess-Modell
zur Beschreibung der Anforderungen benutzt werden.
[Fowler2] S. 6 stellt
fest, dass kein echter empirischer Nachweis existiert, dass die
Techniken
gut oder schlecht sind, die in der UML zur Anwendung kommen. Der
Kunde
will am Ende nur ein Programm, das genau das macht, was er bestellt.
Man
sollte also begründen können, warum man glaubt, dass der
Einsatz
der UML im konkreten Projekt gegenüber anderen Techniken der
Software-Entwicklung einen Vorteil bringt. Fowler schreibt hierzu: Softwareentwicklung
findet eigentlich nur statt, um den Code zu erhalten. Diagramme sind
dabei eigentlich nur nette Bildchen. Kein Benutzer dankt Ihnen für
nette Bildchen.
Benutzer wollen lauffähige Software.
google
zu UML
home - top - Kontakt - letzter Update 20.5.2004 -
© Karl Scharbert